Lecture from: 03.10.2024 | Video: Videos ETHZ | Rui Zhangs Notes | Leetcode: 53. Maximum Subarray
Max Subarray Sum
Imagine you’re given a list of daily stock price changes. Your goal is to determine the maximum profit you could make by buying and selling the stock at most once. This problem, known as the Max Subarray Sum problem, involves finding the subarray with the largest sum, representing the period where your investment yields the highest return.
Algorithm 0: The Naive Approach ()
A simple solution is to consider every possible subarray:
Pseudocode:
def max_subarray_sum_naive(array):
max_sum = 0
for i in range(len(array)):
for j in range(i, len(array)):
current_sum = 0
for k in range(i, j):
current_sum += array[k]
max_sum = max(max_sum, current_sum)
return max_sumHere, we use three nested loops. The outer loop iterates through starting points (i), the second loop through ending points (j), and the innermost loop calculates the sum for each subarray. While this approach is conceptually straightforward, it suffers from a time complexity of due to the triple nesting.

Algorithm 1: Reduce Duplicate Work ()
When calculating the sum of a subarray from index i to j, we only need the current element (array[j]) plus the sum of the previous subarray (from index i to j-1). This means we can avoid recalculating the entire subarray sum for each iteration.
Pseudocode:
def max_subarray_sum(array):
max_sum = 0
for i in range(len(array)):
current_sum = 0
for j in range(i, len(array)):
current_sum += array[j] # Add the current element
max_sum = max(max_sum, current_sum) # Update max_sum if needed
return max_sumExplanation:
- Initialization:
max_sumis initialized to negative infinity to ensure that any valid subarray sum will be greater. - Outer Loop (
i): This loop iterates through each element as a potential starting point for a subarray. - Inner Loop (
j): This loop extends the subarray from indexito the current positionj.current_sumis updated by adding the value atarray[j].- We compare
current_sumwithmax_sumand updatemax_sumifcurrent_sumis larger.
Time Complexity:
The nested loops result in time complexity because the inner loop iterates n-i times for each iteration of the outer loop.
In this current algorithm we are calculating all the possible subarray sums. If we want to improve the time complexity of this algorithm, we need to start thinking how to not need to calculate all the subarray sums (since we can’t reduce the operations more while also calculating all the sums).
Algorithm 3: Divide and Conquer ()
This algorithm leverages the concept of divide and conquer to efficiently solve the Max Subarray Sum problem.
Steps
-
Split: Divide the input array (
array) into two roughly equal halves:left_halfandright_half. -
Base Case: If either half contains only one element, its sum is the maximum subarray sum for that half.
-
Recurse:
- Find the maximum subarray sum (
max_left) withinleft_halfrecursively. - Find the maximum subarray sum (
max_right) withinright_halfrecursively.
- Find the maximum subarray sum (
-
Combine:
- Calculate the
cross_sum: The sum of a subarray spanning both halves. Find the maximumcross_sumby considering all possible starting points inleft_halfand ending points inright_half. - The overall maximum subarray sum (
max_sum) is the largest among:max_left(maximum subarray sum in the left half)max_right(maximum subarray sum in the right half)cross_sum(maximum subarray sum spanning both halves)
- Calculate the
-
Return: Return
max_sum.
Calculating cross_sum
The maximum sum subarray spanning both halves (cross_sum) can be broken down into two parts:
To calculate this efficiently, we can adapt the idea from Algorithm 2. Instead of iterating through all possible pairs (i, j), we fix one pointer (either i or j) and incrementally move the other.
For each fixed position, we calculate the maximum subarray sum by:
- Starting from that fixed point.
- Iteratively moving the free pointer and adding its value to the running sum.
- Updating the maximum sum encountered during this process.
This will give us additions for each half which means that in total we need additions to find the cross_sum.
Pseudocode:
def max_subarray_sum(array):
if len(array) == 1:
return array[0] # Base Case: Single element
midpoint = len(array) // 2
left_half = array[:midpoint]
right_half = array[midpoint:]
max_left = max_subarray_sum(left_half)
max_right = max_subarray_sum(right_half)
cross_sum = calculate_cross_sum(left_half, right_half)
return max(max_left, max_right, cross_sum) # Overall maximum
def calculate_cross_sum(left_half, right_half):
left_max = current_sum = 0
for i in range(len(left_half), -1): # Iterate from midpoint backwards
current_sum += left_half[i]
left_max = max(left_max, current_sum)
right_max = current_sum = 0
for j in range(len(right_half)):
current_sum += right_half[j]
right_max = max(right_max, current_sum)
cross_sum = left_max + right_max
return cross_sumTime Complexity
We can write down the recurrence of additions in the following manner:
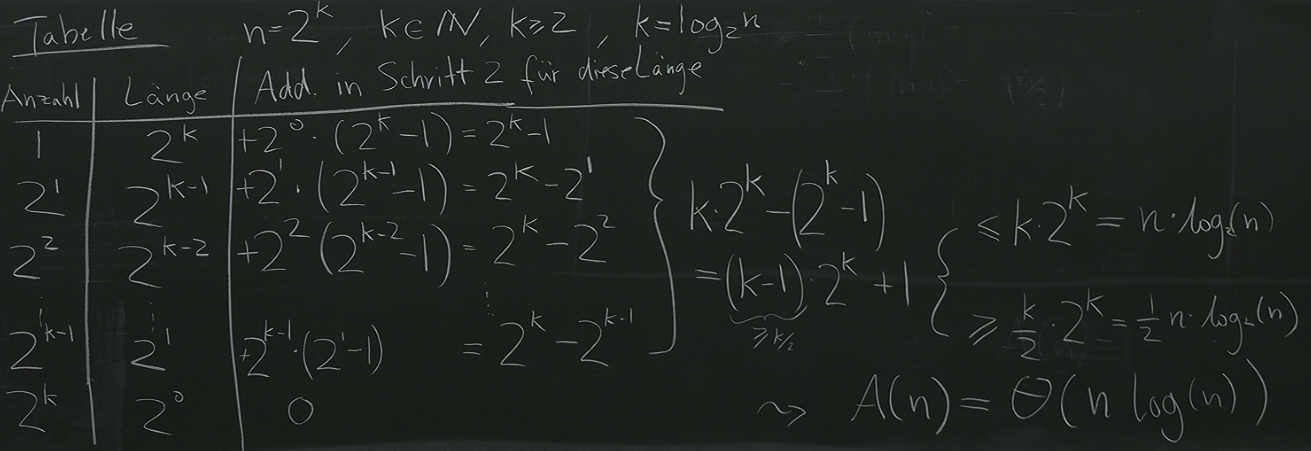
We can see that the time complexity . Buuut, geht es besser???
Algorithm 4: Differently recursively (Kadane’s algorithm)
Currently, we’ve been using the divide and conquer concept on the problem of . But what if we are able to instead do: ?
Let us define , i.e. is the max sub array sum until there. Now we can observe that if we look at and want to find out , we check if is positive, and if so, add it with the number at index to get , if is negative, the number at index will be bigger, so we’ll start a “new subarray” starting there to calculate our further ‘s. This algorithm is called Kadane’s Algorithm.
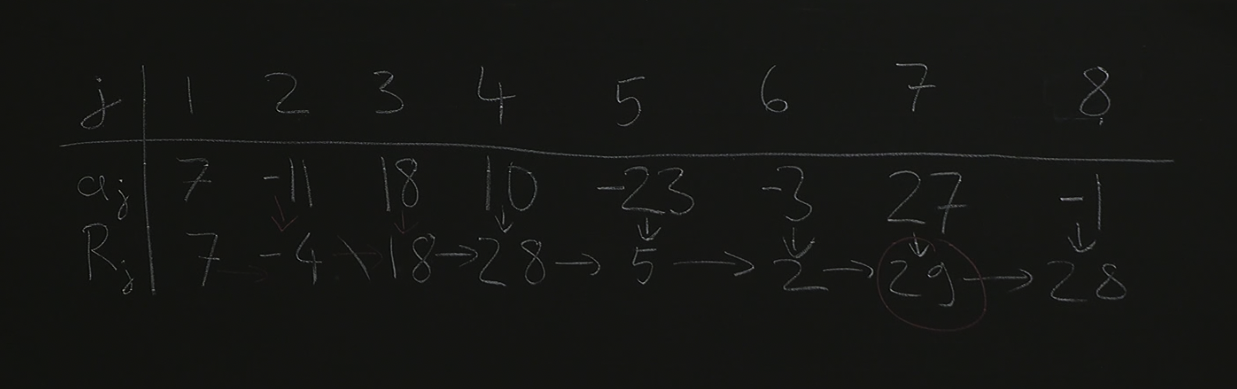
Kadane’s Algorithm provides an efficient solution to the maximum subarray sum problem using dynamic programming. Instead of resorting to divide-and-conquer, Kadane’s Algorithm leverages dynamic programming to efficiently solve the maximum subarray sum problem. The core idea is to iteratively build up a solution by considering the contribution of each element to potential subarrays.
Let R[j] represent the maximum subarray sum ending at index j. We can express this recursively:
- Base Case:
R[0] = a[0](The maximum subarray sum ending at the first index is simply the value at that index). - Recursive Step:
R[j] = max(a[j], R[j-1] + a[j])- If starting a new subarray at index
jyields a greater sum (a[j]), then we updateR[j]. - Otherwise, we extend the previous subarray ending at index
j - 1by adding the current element (R[j-1] + a[j]), ensuring we consider both possibilities.
- If starting a new subarray at index
While recursion can be insightful, it often leads to redundant calculations. Kadane’s Algorithm is typically implemented iteratively for efficiency:
def max_subarray_sum(array):
max_so_far = 0
current_max = 0
for i in range(len(array)):
current_max = max(0, current_max + array[i]) # Extend or start a new subarray
max_so_far = max(max_so_far, current_max) # Update overall maximum sum
return max_so_farTime complexity
This algorithm runs at . This is because we iterate through the array only once to calculate the maximum subarray sum.
Buuut, geht es besser??? → Not really, because we can’t really skip look at each element and still calculate the max subarray sum. Every correct Algorithm for this problem must at least run reading operations and thereby must run at .