Lecture from 04.10.2024 | Video: Videos ETHZ
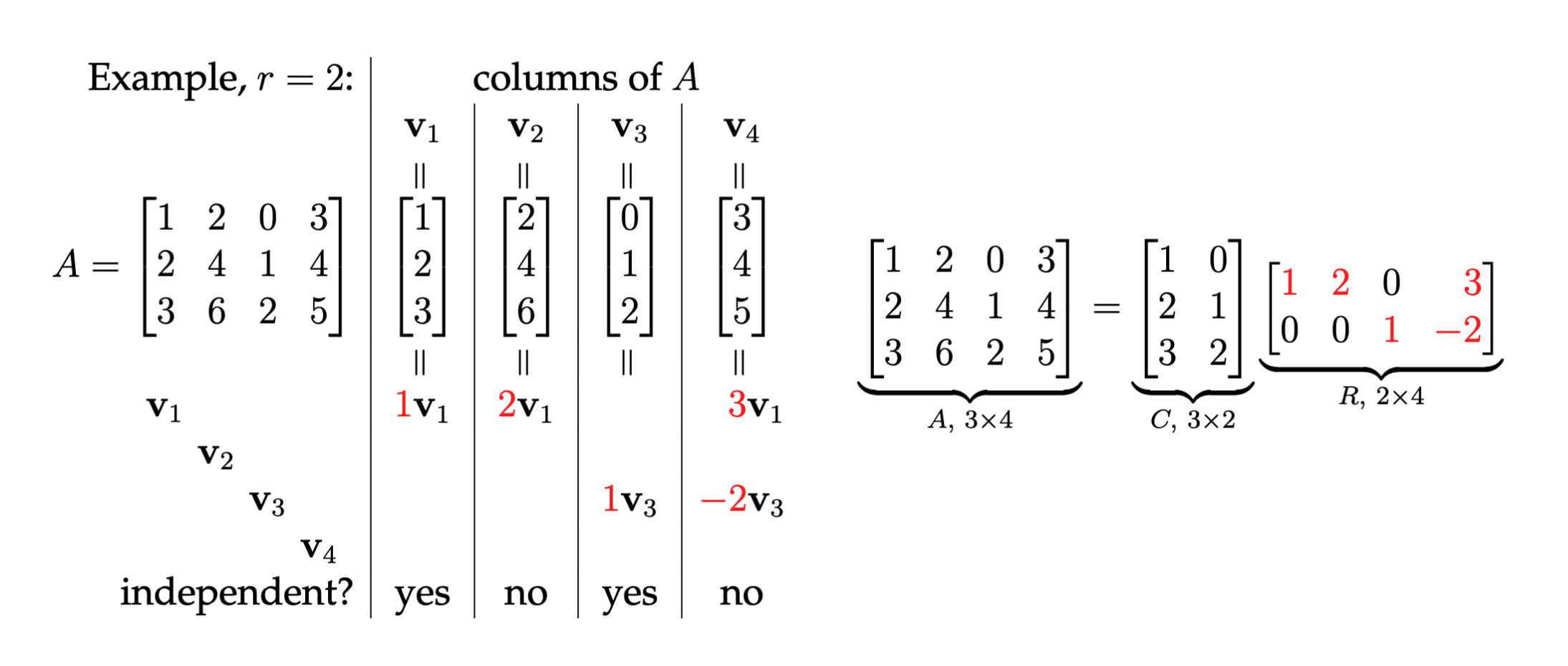
CR-Factorization
Imagine an matrix, , with a rank of r. This means its columns span an r-dimensional space. CR-Factorization says we can build from two special matrices:
- C: A smaller matrix containing only the independent columns of . These columns form a solid foundation, acting as a basis for the entire column space of . Think of them as the “essential” building blocks.
- R: A unique matrix that describes how the remaining columns of relate to these independent ones. It essentially encodes the “dependencies” between columns.
The beauty of CR-Factorization lies in this simple equation:
This means we can reconstruct the original matrix, , simply by multiplying and .
Example Rank 1 Matrix (Lemma 2.21)
Consider the matrix:
This is a matrix where the rows are scalar multiples of each other, meaning the rank of the matrix is 1. We can express this matrix as the outer product of two vectors, which is a characteristic of rank 1 matrices.
According to Lemma 2.21, a matrix has rank 1 if and only if there exist non-zero vectors and such that:
In this case, we can write:
The outer product results in:
Thus, we have successfully expressed matrix as the product of two vectors, confirming that it has rank 1.
Example Rank 2
Fast Fibonacci Numbers by Iterative (Matrix) Squaring

Now what if we wanted to find out ?

 But this takes way to long. How can we do this faster?
But this takes way to long. How can we do this faster?
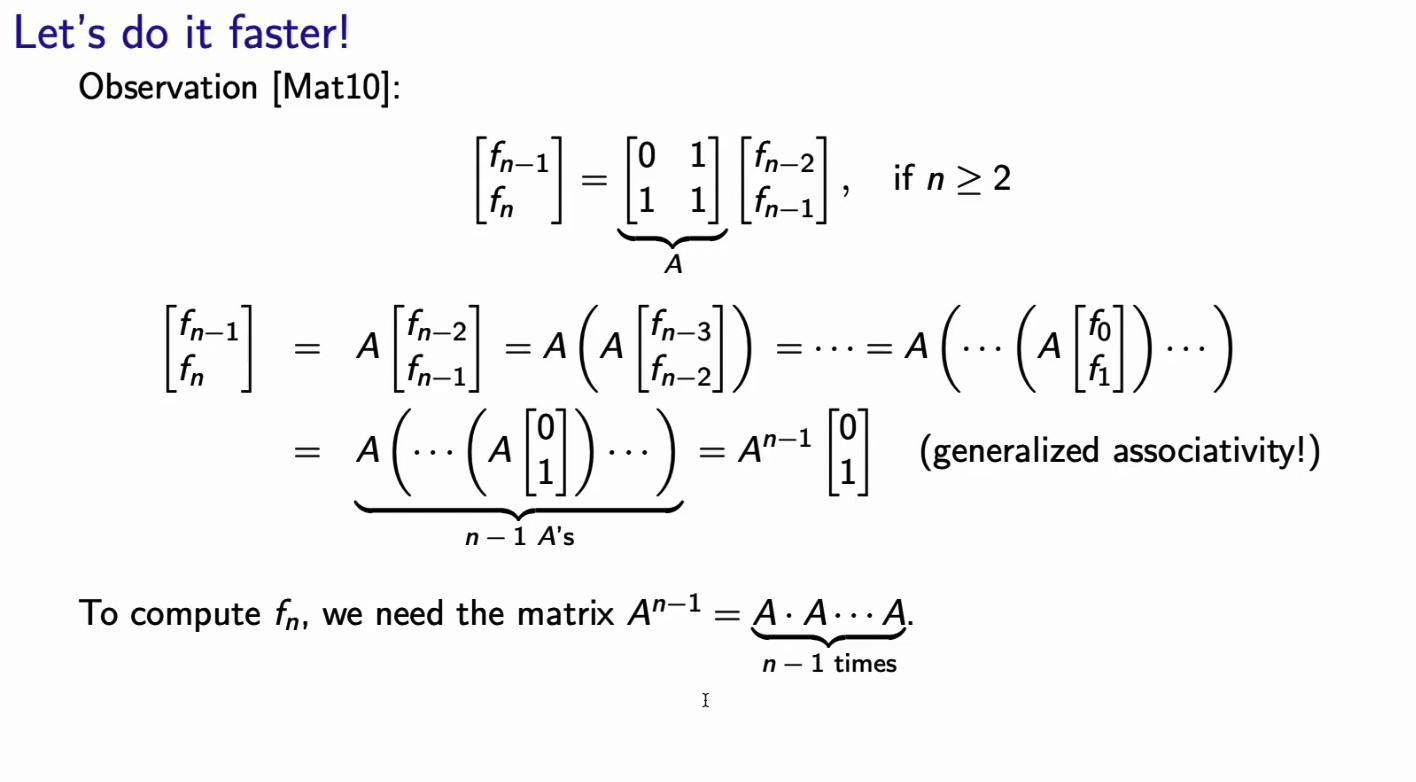
But now we’d have to compute matrix multiplications. We need to have a smarter way of doing that.

Matrices and Linear Transformations
A matrix can be thought of as a function or transformation that maps vectors from one vector space to another. This mapping adheres to the rules of linearity:
-
Additivity: Transforming the sum of two vectors is equivalent to transforming each vector individually and then adding the results. Mathematically, for matrices A and vectors x, y:
-
Homogeneity: Scaling a vector by a scalar before transformation is equivalent to scaling the transformed vector. Mathematically, for a matrix A and vectors x, scalar λ:
These properties are crucial because they allow us to manipulate linear combinations of vectors efficiently using matrix operations.
The standard notation for this transformation is , where A represents the matrix and x is the input vector. This product yields an output vector in a different vector space.
| Input | Matrix | Output |
|---|---|---|
Here:
- : The input vector belongs to an n-dimensional Euclidean space.
- : The matrix, A, is a rectangular array of real numbers with m rows and n columns. It defines the transformation between the spaces.
- : The output vector resides in an m-dimensional Euclidean space, reflecting the dimensionality change induced by the transformation.
Example 1: Matrix Multiplication
If we have a matrix:
and an input vector:
we can multiply them together. This multiplication is not like regular multiplication; it’s a specific process where we take each element of the matrix and combine it with corresponding elements from the vector. The result, , is another vector:
Here, the matrix transformed the vector from (two dimensions) to (three dimensions).
Example 2: Linear Transformation
A linear transformation is a special type of function that preserves certain properties. We can represent it using a matrix. Let’s consider the transformation defined by this matrix:
This matrix “swaps” the components of a vector. Applying the transformation to a vector gives us:
So, if we input , the output is .
Visual Transformation
Let us define that a transformation of a set of inputs is defined as:
Example (): “Space Distortion”:
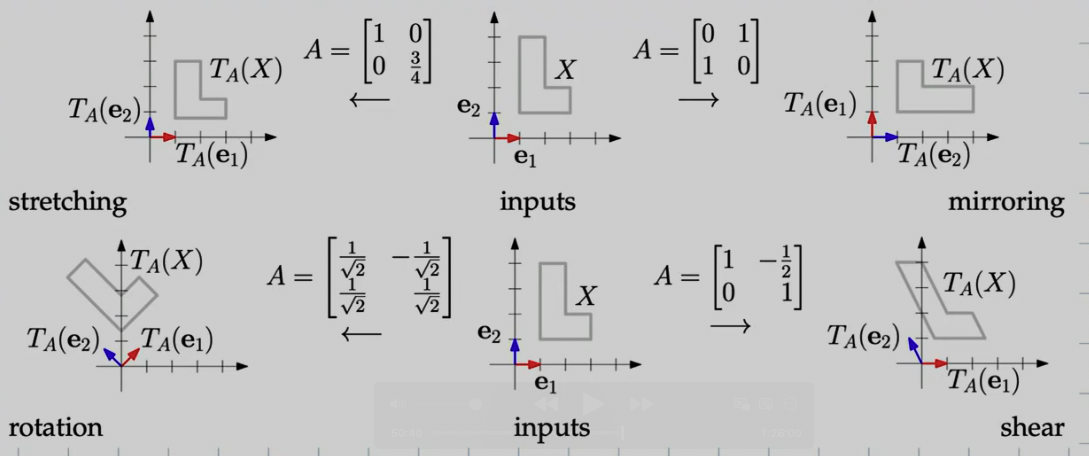
A simple way to think of what’s happening is to look at the unit vectors start and end position. 2D matrices allow you to operate on vectors in RR2 distort them by: stretching, mirroring, rotating, shearing,…
Example : “Orthogonal Projection”
Input 3D unit cube → Output: 2D Projection.
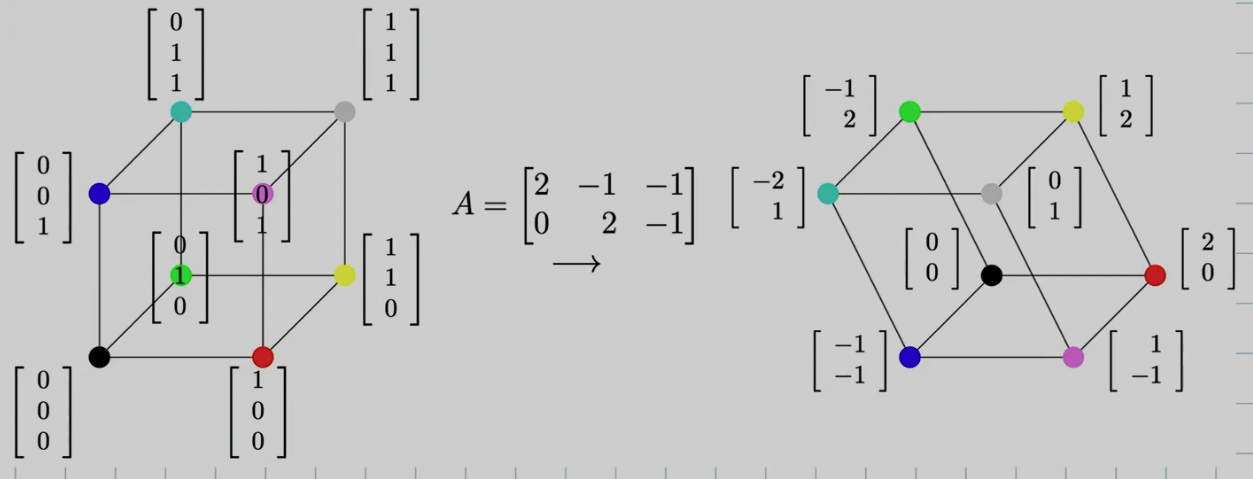
Linear Transformations Generalization
Linear transformations provide a powerful framework for describing how vectors can be transformed in a consistent and predictable manner.
A function is considered a linear transformation if it satisfies the following two axioms for all vectors and any scalar :
-
Additivity:
-
Homogeneity:
Examples
Linear Transformations Represented by Matrices:
- Rotation in 2D: Rotating a vector in the plane by an angle θ can be achieved with the following 2x2 matrix:
- Scaling in ℝ²: To scale a vector in the plane by a factor ‘k’ along both axes, we use the matrix:
- Projection onto the x-axis in ℝ²: This transformation maps any vector (x, y) to (x, 0). The corresponding matrix is:
- Shearing in ℝ²: Shearing a vector distorts its shape by moving points along diagonal lines. A common shear transformation can be represented with the matrix:
where ‘s’ is the shearing factor.
Linear Transformations Without Matrices:
-
Differentiation: The derivative of a function (e.g., ) is a linear transformation because:
- It satisfies additivity:
- It satisfies homogeneity:
-
Integration: Similar to differentiation, the integral of a function (e.g., ) is also a linear transformation.
Continue here: 07 Linear Transformations, Linear Systems of Equations, PageRank