Lecture from 09.10.2024 | Video: Videos ETHZ
Linear Transformations
We showed last time that a transformation is linear if it is additive and homogenous.
Lemma 2.28:
Let be a linear transformation. , then:
To be rigorous let us prove this properly by using induction. We are going to use this method in order to not use the “unrigorous” dotted notation which uses in it’s proof.

The matrix of a linear transformation (Theorem 2.29)
Let be a linear transformation. Then there exists an unique matrix such that .
Now this might seem daunting at first, but once we prove it it makes the job of working with generic linear transformations much easier, since we only have to think of matrices.
Proof:
In order for we need:
which means that the linear transformation of the unit vector is the same for both transformations.
This way the only matrix we can get is:
This works, because for all :
Now using this information we can show some general properties of linear transformations:

Systems of Linear Equations
A system of linear equations is a collection of two or more linear equations involving the same variables. The goal is to find values for these variables that simultaneously satisfy all the equations in the system.
A system of linear equations in equations and n variables is of the form:
Or in a “more simpler” standardized matrix-vector form:
Let us call A: “coefficient matrix”, b = “right side” and x: “vector of the variables”. A and b are known real values. The x vector is the “unknown”.
The following observation (Beobachtung 3.2) becomes trivial:
Let be a a matrix. The columns of A are linearly independent if and only if the system has a single unique trivial solution ().
Pagerank Algorithm (Google)
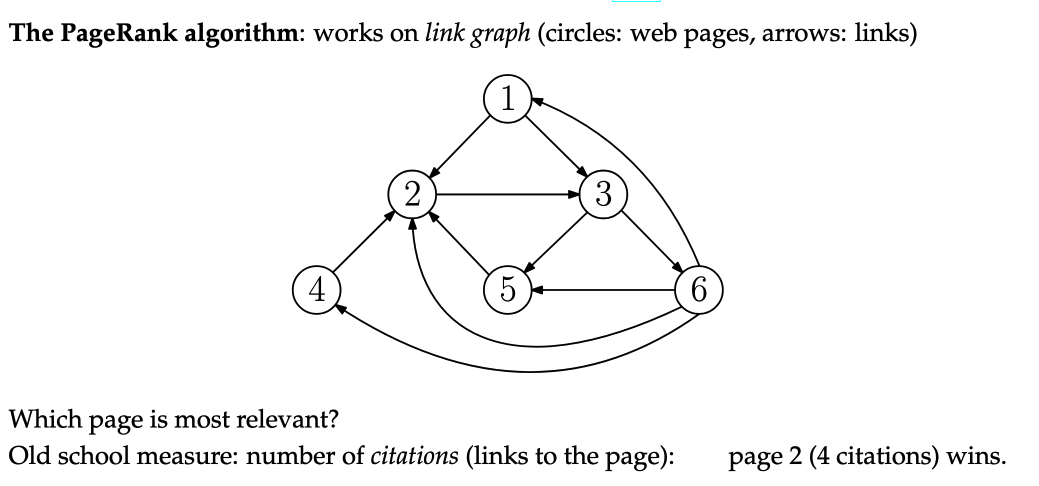
PageRank-Principles:
- Citations from relevant pages are worth more (no spamming links from useless sites)
- Citations from sites which cite a lot of sites are worth less
Now you might see that we have a small problem. We want to define the rank of a page based on the rank of other pages (which is also based on the rank of other pages…), effectively creating a recursive problem.
Relevance: Sum of the relevance of the sites citing this site, divided by the number of sites which are sited on that site.
Analogously for the other sites…
And wow, look at this, we got a system of 6 linear equations and 6 variables (sites). Unfortunately we have a useless solution of .
Fix:
We will use a slight approximation using a damping factor close to (for example, ):
This now allows us to have a unique (non-trivial) solution to our problem ():
Page 3 (rank 1.7307) wins.
Continue here: 08 Gauss Elimination, Elimination Matrices and Solution Sets